
LeetCode Hot 100 题解合集 (1-50)
title1 - 两数之和
SumOfTwoNumber.java
java
package leecode100.title1;
import java.util.HashMap;
/**
* 题目:给定一个整数数组 nums 和 an 整数目标值 target,
* 请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
* 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
* 你可以按任意顺序返回答案。
* 输入:nums = [2,7,11,15], target = 9
* 输出:[0,1]
* 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
*/
public class SumOfTwoNumber {
/*
思路:利用hashmap时间复杂度可以降到o1
hashmap以key value存储,其中key存储value,value存储index
diff = target-num[i]
遍历nums如果这个diff在hashmap的key中存在,直接返回i和hashmap.get(diff)
*/
public static void main(String[] args) {
int[] numbers = new int[]{2, 7, 11, 15};
int[] indexs = new SumOfTwoNumber().twoSum(numbers, 9);
for (int i = indexs.length - 1; i >= 0; i--) {
System.out.print(indexs[i] + " ");
}
}
// 1.暴力求解,两重for循环分别代表起始元素
// 2.用HashMap,时间复杂度为O(n),空间复杂度为O(n);
// 两个数之和 = target 那么就是target - 其中一个数 = 另外一个target
// 一重for循环,遍历整个数组,将出现过的值加入到hashmap中,key为值,value为索引
// 对于当前元素,hashmap.contiansKey(target - value) ,则找到两个数
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
HashMap<Integer, Integer> hs = new HashMap();
for (int i = 0; i < nums.length; i++) {
int diff = target - nums[i];
if (hs.containsKey(diff)) {
res[1] = i;
res[0] = hs.get(diff);
break;
}
hs.put(nums[i],i);
}
return res;
}
}title2 - 字母异位词分组
DiffPlaceButSameWord.java
java
package leecode100.title2;
import java.util.*;
/**
* 题目:字母异位词分组
* 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
* 输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
* 输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
* 解释:
* 在 strs 中没有字符串可以通过重新排列来形成 "bat"。
* 字符串 "nat" 和 "tan" 是字母异位词,因为它们可以重新排列以形成彼此。
* 字符串 "ate" ,"eat" 和 "tea" 是字母异位词,因为它们可以重新排列以形成彼此。
*/
public class DiffPlaceButSameWord {
/**
* 利用排序将eat->ate tea->ate 可以将他们归为一组
* 思路:设计一个哈希表 键值对 key使用排序后的单词 value为异位词
*/
public static void main(String[] args) {
String[] strs = new String[]{"eat", "tea", "tan", "ate", "nat", "bat"};
List<List<String>> lists =
new DiffPlaceButSameWord().groupAnagrams(strs);
lists.forEach(System.out::println);
}
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List<String>> hashmap = new HashMap<String, List<String>>();
for (int i = 0; i < strs.length; i++) {
String word = strs[i];
char[] wordCharArray = word.toCharArray();
Arrays.sort(wordCharArray);
String key = new String(wordCharArray);
List<String> defaultList = hashmap.getOrDefault(key, new ArrayList<>());
defaultList.add(word);
hashmap.put(key, defaultList);
}
return new ArrayList<>(hashmap.values());
}
}title3 - 最长连续序列
LongestConsecutive.java
java
package leecode100.title3;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* 题目:最长连续序列
* 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
* 请你设计并实现时间复杂度为 O(n) 的算法解决此问题
* 输入:nums = [100,4,200,1,3,2]
* 输出:4
* 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
*/
public class LongestConsecutive {
/**
* 思路:先将所有的数字存放到hashmap之中,
* 然后遍历number去看hashmap是否存在,如果存在number+1,再去hashmap看是否存在,一直统计
* 如果不存在就检查下一个number
*/
public static void main(String[] args) {
int[] nums = new int[]{100,4,200,1,3,2};
int count = new LongestConsecutive().longestConsecutive(nums);
System.out.println(count);
}
public int longestConsecutive(int[] nums) {
if(nums.length == 0 || nums.length == 1){
return nums.length;
}
HashMap<Integer,Integer> hs = new HashMap<>();
for(int i = 0; i<nums.length; i++){
hs.put(nums[i],i);
}
int res = -65535;
Set<Integer> keyset = hs.keySet();
for(Integer key: keyset){
// 只有当key-1不存在时,才开始统计连续序列长度
if(!hs.containsKey(key-1)){
int cnt = 0;
while(hs.containsKey(key)){
cnt++;
key++;
}
res = Math.max(cnt,res);
}
}
return res;
}
}title4 - 移动零
MoveZero.java
java
package leecode100.title4;
/**
* 题目:
* 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
* 请注意 ,必须在不复制数组的情况下原地对数组进行操作。
* 输入: nums = [0,1,0,3,12]
* 输出: [1,3,12,0,0]
*/
public class MoveZero {
public static void main(String[] args) {
int[] nums = new int[]{0, 1, 0, 3, 12};
new MoveZero().moveZeroes(nums);
for (int num : nums) {
System.out.print(num + " ");
}
}
/*
思路:利用双指针 因为要保持相对顺序 所以利用一个left指针指向非零元素的的位置 利用另一个right指针进行遍历
最后将left指针后面的所有的元素替换为0
*/
public void moveZeroes(int[] nums) {
int l = 0,r=0;
while(r<nums.length){
if(nums[r]!=0){
nums[l] = nums[r];
l++;
}
r++;
}
while(l<nums.length){
nums[l]=0;
l++;
}
return ;
}
}title5 - 盛最多水的容器
MaxWaterArea.java
java
package leecode100.title5;
/**
* 题目:
* 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
* 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
* 返回容器可以储存的最大水量。
* 输入:[1,8,6,2,5,4,8,3,7]
* 输出:49
* 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
*/
public class MaxWaterArea {
/**
* 利用双指针 left指针在数组开头 right指针在数据结尾 只需要移动高度较小的指针面积才有可能变大 最后指导两个指针相遇即可结束
*/
public static void main(String[] args) {
int[] height = new int[]{1, 8, 6, 2, 5, 4, 8, 3, 7};
int maxArea = new MaxWaterArea().maxArea(height);
System.out.println(maxArea);
}
public int maxArea(int[] height) {
int l=0,r= height.length-1;
int res=0;
while(l<r){
int path = Math.min(height[l],height[r])*(r-l);
res = Math.max(res,path);
// 易错点:只移动较小高度的指针
if(height[l]>height[r]) r--;
else l++;
}
return res;
}
}title6 - 三数之和
SumOfThreeNumbers.java
java
package leecode100.title6;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 题目:
* 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]]
* 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
* 注意:答案中不可以包含重复的三元组。
* 输入:nums = [-1,0,1,2,-1,-4]
* 输出:[[-1,-1,2],[-1,0,1]]
* 解释:
* nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
* nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
* nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
* 不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
* 注意,输出的顺序和三元组的顺序并不重要。
*/
public class SumOfThreeNumbers {
/**
* 思路:先将数组排序,然后利用双指针,固定一个num[i],left指针指向i+1,right指针指向num.length-1,利用-nums[i]=nums[j]+nums[k]这个关系去找,
* 如果nums[j]+nums[k]<-num[i], 说明和不够,left移动,left++,反之,right--,因为之前是顺序存储。
* 注意:有几个地方需要去重,第一个固定住的num[i]和num[i-1],另一个是当移动left指针的时候如果num[left]和number[left-1],最后一个是移动right,num[right]和num[right+1]
*/
public static void main(String[] args) {
// int[] numbers = new int[]{1, -1, -1, 0};
int[] numbers = new int[]{-1, 0, 1, 2, -1, -4};
List<List<Integer>> list = new SumOfThreeNumbers().threeSum(numbers);
for (List<Integer> integers : list) {
System.out.println(integers);
}
}
public List<List<Integer>> threeSum(int[] nums) {
int len = nums.length;
List<List<Integer>> res = new ArrayList<>();
if (len < 3) return res;
Arrays.sort(nums);
for (int i = 0; i < len - 2; i++) {
if (i > 0 && nums[i] == nums[i - 1]) {
continue;
}
int l = i + 1;
int r = len - 1;
while (l < r) {
if (l > i + 1 && nums[l] == nums[l - 1]) {
l++;
continue;
}
if (r < len - 1 && nums[r] == nums[r + 1]) {
r--;
continue;
}
if (nums[l] + nums[r] == -nums[i]) {
res.add(Arrays.asList(nums[i], nums[l], nums[r]));
l++;
r--;
continue;
}
if (nums[l] + nums[r] < -nums[i]) l++;
else r--;
}
}
return res;
}
}title7 - 接雨水
GetRainWater.java
java
package leecode100.title7;
/**
* 题目:给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
* 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
* 输出:6
* 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
*/
public class GetRainWater {
/**
* 思路:某大厂算法题 见过一次就秒 没见过想不出来 记住过程即可
* 要计算某个位置的积水量,需要知道该位置左右两侧的最大高度。
* 积水量 = min(左边最大高度, 右边最大高度) - 当前柱子高度(如果结果为负,则积水量为0)。
* 遍历每个位置,计算其积水量并累加,得到总积水量。
*/
public static void main(String[] args) {
int[] nums = new int[]{0, 1, 0, 2, 1, 0, 1, 3, 2, 1, 2, 1};
int trap = new GetRainWater().trap(nums);
System.out.println(trap);
}
public int trap(int[] height) {
int len = height.length;
//可以先用两数组存储每个位置左右两侧高度的最大值 用空间换时间
int[] l = new int[len];
int[] r = new int[len];
l[0] = 0;
r[len - 1] = 0;
for (int i = 1; i < len; i++) {
// l[i] = Math.max(l[i-1],height[i]);
l[i] = Math.max(l[i - 1], height[i - 1]);
}
for (int i = len - 2; i >= 0; i--) {
// r[i] = Math.max(r[i+1],height[i]);
r[i] = Math.max(r[i + 1], height[i + 1]);
}
int res = 0;
for (int i = 0; i < len; i++) {
res += Math.max(0, Math.min(l[i], r[i]) - height[i]);
}
return res;
}
}title8 - 无重复字符的最长子串
LongestSubStringLength.java
java
package leecode100.title8;
import java.util.HashMap;
import java.util.HashSet;
/**
* 题目:给定一个字符串 s ,请你找出其中不含有重复字符的最长子串的长度。
* 输入: s = "abcabcbb"
* 输出: 3
* 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
*/
public class LongestSubStringLength {
/**
数据结构选择:使用 HashSet<Character> 维护滑动窗口,存储当前无重复字符的子串
双指针策略:left 指针控制窗口左边界,right 指针扩展右边界
窗口扩展:遍历字符串,每次将 right 指向的字符加入窗口
重复处理:当遇到重复字符时,持续移除 left 指向的字符并右移 left 指针,直到窗口中无重复
长度更新:每次成功扩展窗口后,更新 maxLength 为当前窗口大小的最大值
*/
public static void main(String[] args) {
String s = "pwwkew";
int result = new LongestSubStringLength().lengthOfLongestSubstring(s);
System.out.println(result);
}
public int lengthOfLongestSubstring(String s) {
int left = 0;
int maxLength = 0;
HashSet<Character> window = new HashSet<>(); // 使用HashSet存储窗口中的字符
for (int right = 0; right < s.length(); right++) {
char c = s.charAt(right);
// 如果字符已存在,收缩左边界直到没有重复
while (window.contains(c)) {
window.remove(s.charAt(left));
left++;
}
// 添加当前字符到窗口
window.add(c);
// 更新最大长度
maxLength = Math.max(maxLength, right - left + 1);
}
return maxLength;
}
}title9 - 找到字符串中所有字母异位词
FindAllDiffPlaceWord.java
java
package leecode100.title9;
import java.util.*;
/**
* 题目:
* 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
* 示例 1:
* <p>
* 输入: s = "cbaebabacd", p = "abc"
* 输出: [0,6]
* 解释:
* 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
* 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
*/
public class FindAllDiffPlaceWord {
/**
* 思路:滑动窗口思想。固定一个大小为p长度的窗口,不断移动,
* 计算窗口中字符出现的频次与p中字符频次是否相同,如果相同就是异位词,反之,则不是。
* 用什么来存储字符的频次呢,可以用hashmap但是时间复杂度过大,可以直接用数组,利用随机存取的特性降低时间复杂度。
* 两个数组 snum和pnum 先存放第一组数据,进行比较,后续遍历进行滑动窗口,移除窗口最左端字符,添加窗口最右端字符,然后进行比较。
*/
public static void main(String[] args) {
String s = "cbaebabacd";
String p = "abc";
List<Integer> list = new FindAllDiffPlaceWord().findAnagrams(s, p);
list.forEach(System.out::println);
}
public List<Integer> findAnagrams(String s, String p) {
int slen = s.length();
int plen = p.length();
List<Integer> res = new ArrayList<>();
if (slen < plen) return res;
int[] pnum = new int[26];
int[] snum = new int[26];
for (int i = 0; i < plen; i++) {
pnum[p.charAt(i) - 'a']++;
snum[s.charAt(i) - 'a']++;
}
if (Arrays.equals(pnum, snum)) res.add(0);
for (int i = plen; i < slen; i++) {
snum[s.charAt(i) - 'a']++;
snum[s.charAt(i - plen) - 'a']--;
if (Arrays.equals(pnum, snum)) res.add(i - plen + 1);
}
return res;
}
}title10 - 和为 K 的子数组
KSumSubArray.java
java
package leecode100.title10;
import java.util.HashMap;
/**
* 题目:
* 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
* 子数组是数组中元素的连续非空序列。
* 示例 1:
* 输入:nums = [1,1,1], k = 2
* 输出:2
* 示例 2:
* 输入:nums = [1,2,3], k = 3
* 输出:2
*/
public class KSumSubArray {
/**
* 思路:遍历数组,统计前缀和并且将前缀和以及出现的次数,放入hashmap之中。
* 后续利用s[j]-k去hashmap之中去找对应的前缀次数即可。
*/
public static void main(String[] args) {
// int[] nums = new int[]{1, 1, 1};
// int result = new KSumSubArray().subarraySum(nums, 2);
int[] nums = new int[]{1, 2, 3};
int result = new KSumSubArray().subarraySum(nums, 3);
System.out.println(result);
}
/**
* 模拟运行过程:1,1,1 k=2
* sum = 0,1,2
* hashmap=
*/
public int subarraySum(int[] nums, int k) {
HashMap<Integer, Integer> hs = new HashMap<>();
hs.put(0, 1);
int res = 0;
int presum = 0;
for (int i = 0; i < nums.length; i++) {
presum += nums[i];
int cnt = hs.getOrDefault(presum - k, 0);
res += cnt;
int newvalue = hs.getOrDefault(presum, 0) + 1;
hs.put(presum, newvalue);
}
return res;
}
}title11 - 滑动窗口最大值
MaxSliderWindows.java
java
package leecode100.title11;
import java.util.ArrayList;
import java.util.LinkedList;
/**
* 题目:滑动窗口最大值
* 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
* 返回 滑动窗口中的最大值 。
* 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
* 输出:[3,3,5,5,6,7]
* 解释:
* 滑动窗口的位置 最大值
* --------------- -----
* [1 3 -1] -3 5 3 6 7 3
* 1 [3 -1 -3] 5 3 6 7 3
* 1 3 [-1 -3 5] 3 6 7 5
* 1 3 -1 [-3 5 3] 6 7 5
* 1 3 -1 -3 [5 3 6] 7 6
* 1 3 -1 -3 5 [3 6 7] 7
*/
public class MaxSliderWindows {
public static void main(String[] args) {
int[] nums = new int[]{1, 3, -1, -3, 5, 3, 6, 7};
int[] results = new MaxSliderWindows().maxSlidingWindow(nums, 3);
for (int result : results) {
System.out.print(result + " ");
}
}
/**
* 下面是ai给出的建议:
* 你的代码实现了一个滑动窗口最大值问题,但时间复杂度较高,主要是因为每次滑动窗口时,
* 你都通过遍历整个窗口(sliderQueue)来重新计算最大值,导致整体时间复杂度为 O(n * k),
* 其中 n 是数组长度,k 是窗口大小。为了优化时间复杂度,可以使用 单调队列(Monotonic Queue) 或 双端队列(Deque) 来维护窗口内的最大值,
* 使得每次滑动窗口时都能以 O(1) 或均摊 O(1) 的复杂度获取最大值。
* 优化后的时间复杂度可以降到 O(n)。
**/
public int[] maxSlidingWindow(int[] nums, int k) {
ArrayList<Integer> resultList = new ArrayList<>();
LinkedList<Integer> sliderQueue = new LinkedList<>();
int max = Integer.MIN_VALUE;
//将第一轮的数据放入sidernum;
for (int i = 0; i < k; i++) {
sliderQueue.addLast(nums[i]);
}
//记录队列中的最大值
for (int value : sliderQueue) {
max = Math.max(max, value); // 直接比较队列中的值
}
resultList.add(max);
//进行滑动窗口的移动
for (int i = k; i <= nums.length - 1; i++) {
//移除队头第一个元素,从队尾添加
Integer removeFirst = sliderQueue.removeFirst();
sliderQueue.addLast(nums[i]);//从队尾添加一个元素
// 如果移除的元素不是最大值,且新元素小于等于当前最大值
if (removeFirst != max && nums[i] <= max) {
// 最大值不变,直接使用
resultList.add(max);
} else {
// 如果移除的是最大值,或者新元素可能更大,需要重新找最大值
max = Integer.MIN_VALUE;
for (int value : sliderQueue) { //没有解决本质的问题
max = Math.max(max, value);
}
resultList.add(max);
}
}
//将集合转为数组
int[] result = new int[resultList.size()];
for (int i = 0; i < resultList.size(); i++) {
result[i] = resultList.get(i);
}
return result;
}
}title12 - 最小覆盖子串
MinCoverSubString.java
java
package leecode100.title12;
import java.util.HashMap;
/**
* 题目:
* 给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
* 注意:
* 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
* 如果 s 中存在这样的子串,我们保证它是唯一的答案。
*
* 示例 1:
* 输入:s = "ADOBECODEBANC", t = "ABC"
* 输出:"BANC"
* 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
*/
public class MinCoverSubString {
/**
* 思路:利用滑动窗口的机制,向右边扩大窗口直到满足条件,记录答案值,尝试缩小窗口记录最小覆盖的子串。
* 右扩左收窗口滑,
* 需求满足就更新,
* valid计数是关键,
* 双指针法解此类题。
*/
public static void main(String[] args) {
String s = "ADOBECODEBANC";
String t = "ABC";
String result = new MinCoverSubString().minWindow(s, t);
System.out.println(result);
}
public String minWindow(String s, String t) {
int left = 0, right = 0;
int valid = 0;
int start = 0;
int len = Integer.MAX_VALUE;
HashMap<Character, Integer> need = new HashMap<>();
HashMap<Character, Integer> window = new HashMap<>();
// 初始化needMap
for (char c : t.toCharArray()) {
need.put(c, need.getOrDefault(c, 0) + 1);
}
// 滑动窗口主循环
while (right < s.length()) { // 简化循环条件
char c = s.charAt(right++);
// 扩大窗口
if (need.containsKey(c)) {
window.put(c, window.getOrDefault(c, 0) + 1);
if (window.get(c).equals(need.get(c))) {
valid++;
}
}
// 收缩窗口
while (valid == need.size()) {
// 更新最小覆盖子串
if (right - left < len) {
start = left;
len = right - left;
}
char d = s.charAt(left++);
if (need.containsKey(d)) {
if (window.get(d).equals(need.get(d))) {
valid--;
}
window.put(d, window.get(d) - 1);
}
}
}
return len == Integer.MAX_VALUE ? "" : s.substring(start, start + len);
}
}title13 - 最大子数组和
MaxSubArraySum.java
java
package leecode100.title13;
/**
* 最大子数组和
* 题目:给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
* 子数组是数组中的一个连续部分。
* 输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
* 输出:6
* 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
*/
public class MaxSubArraySum {
/**
* 思路: kadane算法,动态规划的应用 最优子结构 重叠子问题 可以用一个临时的变量记录下来
* 核心解题思路:计算当前位置的最大和取决于当前位置大还是以这个数结尾的子数组之和大。
* 有一个很好玩的应用就是股票收益,当前你是否需要加仓还是清仓,取决于当天的收益大还是之前连续的某一天收益大。
*/
public static void main(String[] args) {
int[] nums = new int[]{-2,1,-3,4,-1,2,1,-5,4};
int result = new MaxSubArraySum().maxSubArray(nums);
System.out.println(result);
}
public int maxSubArray(int[] nums) {
if (nums == null || nums.length == 0) {
return Integer.MIN_VALUE;
}
int currentSum = nums[0];
int maxSum = nums[0];
for (int i = 1; i < nums.length; i++) {
currentSum = currentSum + nums[i];
currentSum = Math.max(currentSum,nums[i]);;
maxSum = Math.max(currentSum,maxSum);
}
return maxSum;
}
}title14 - 合并区间
MergeArray.java
java
package leecode100.title14;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
/**
* 合并区间
* 题目:
* 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。
* 请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
* 示例 1:
* 输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
* 输出:[[1,6],[8,10],[15,18]]
* 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
* 示例 2:
* 输入:intervals = [[1,4],[4,5]]
* 输出:[[1,5]]
* 解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
* 1 <= intervals.length <= 104
* intervals[i].length == 2
* 0 <= starti <= endi <= 104
*/
public class MergeArray {
/**
* 思路:将里面的数组进行排序,然后检查当前区间和结果区间进行对比,如果当前区间的start下表的值在结果区间之中,合并区间,否则不合并。
*/
public static void main(String[] args) {
int[][] intervals = new int[][]{{1, 4}, {0, 4}};
int[][] merge = new MergeArray().merge(intervals);
for (int[] interval : merge) {
System.out.println("[" + interval[0] + ", " + interval[1] + "]");
}
}
public int[][] merge(int[][] intervals) {
int[][] res = new int[intervals.length][];
int idx = -1;
Arrays.sort(intervals, Comparator.comparingInt(a -> a[0]));
for (int i = 0; i < intervals.length; i++) {
int st = intervals[i][0];
int end = intervals[i][1];
if (idx == -1 || st > res[idx][1]) {
idx++;
res[idx] = intervals[i];
} else {
//如果temp的值大于结果集中最后一个数组的第二个数的大小,进行合并
res[idx][0] = Math.min(res[idx][0], st);
res[idx][1] = Math.max(res[idx][1], end);
}
}
return Arrays.copyOf(res, idx + 1);
}
}title15 - 轮转数组
RotateArray.java
java
package leecode100.title15;
/**
* 旋转数组:
* 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
* 示例 1:
* 输入: nums = [1,2,3,4,5,6,7], k = 3
* 输出: [5,6,7,1,2,3,4]
* 解释:
* 向右轮转 1 步: [7,1,2,3,4,5,6]
* 向右轮转 2 步: [6,7,1,2,3,4,5]
* 向右轮转 3 步: [5,6,7,1,2,3,4]
* <p>
* 示例 2:
* 输入:nums = [-1,-100,3,99], k = 2
* 输出:[3,99,-1,-100]
* 解释:
* 向右轮转 1 步: [99,-1,-100,3]
* 向右轮转 2 步: [3,99,-1,-100]
* <p>
* 提示:
* 1 <= nums.length <= 105
* -231 <= nums[i] <= 231 - 1
* 0 <= k <= 105
*/
public class RotateArray {
/***
* 思路:利用循环队列的思想,当前数组中的值替换为 i + k % length 即可
*/
public static void main(String[] args) {
int[] num = new int[]{1, 2, 3, 4, 5, 6, 7}; //7
int k = 3;
new RotateArray().rotate(num, k);
for (int i = 0; i < num.length; i++) {
System.out.println("排序后的数组为:" + num[i] + " ");
}
}
public void rotate(int[] nums, int k) {
int[] result = new int[nums.length];
for (int i = 0; i < nums.length; i++) {
result[(i + k) % nums.length] = nums[i];
}
for (int i = 0; i < nums.length; i++) {
nums[i] =result[i];
}
}
}title16 - 除自身以外数组的乘积
MutifyArrayWithoutSelf.java
java
package leecode100.title16;
package leecode100.title16;
/**
* 题目:
* 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
* 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
* 请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
* 示例 1:
* 输入: nums = [1,2,3,4]
* 输出: [24,12,8,6]
* 示例 2:
* 输入: nums = [-1,1,0,-3,3]
* 输出: [0,0,9,0,0]
*/
public class MutifyArrayWithoutSelf {
/**
* 思路:当前数值除它本身以外的乘积可以使用前缀乘积和后缀乘积实现即可
*/
public static void main(String[] args) {
int[] num = new int[]{-1, 1, 2, -3, 3};
int[] result = new MutifyArrayWithoutSelf().productExceptSelf(num);
for (int i = 0; i < result.length; i++) {
System.out.println(result[i]);
}
}
public int[] productExceptSelf(int[] nums) {
int len = nums.length;
int[] ans = new int[len];
ans[0] = 1;
for (int i = 1; i < len; i++) {
ans[i] = ans[i - 1] * nums[i - 1];
}
int[] lastx = new int[len];
lastx[len - 1] = 1;
for (int i = len - 2; i >= 0; i--) {
lastx[i] = lastx[i + 1] * nums[i + 1];
ans[i] *= lastx[i];
}
return ans;
}
}title17 - 缺失第一个正数
LackFirstPostiveNumber.java
数值为 i 的数映射到下标为 i - 1 的位置。 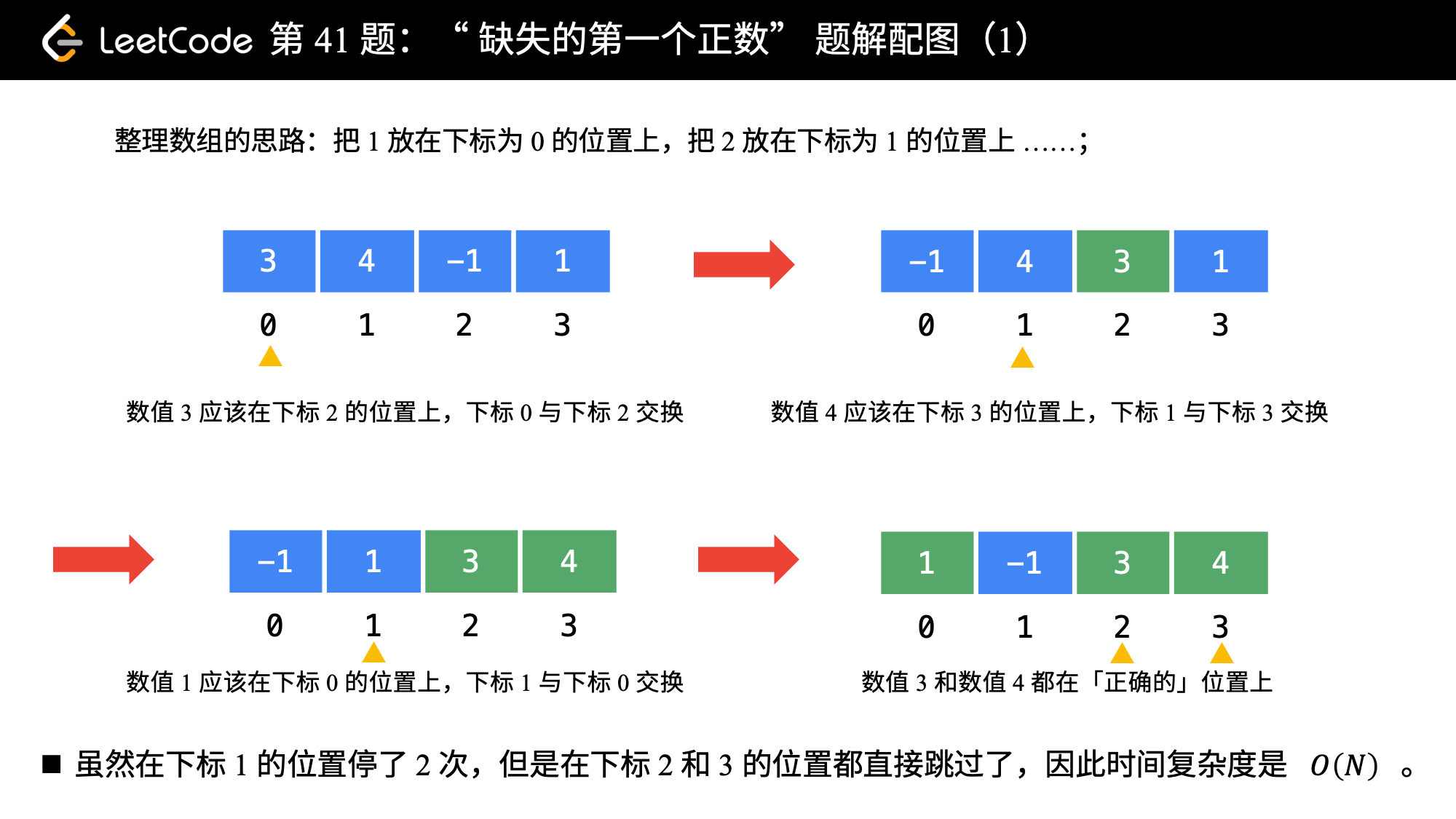
java
package leecode100.title17;
/**
* 缺失第一个整数
* 题目:给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
* 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
* 示例 1:
* 输入:nums = [1,2,0]
* 输出:3
* 解释:范围 [1,2] 中的数字都在数组中。
* 示例 2:
* 输入:nums = [3,4,-1,1]
* 输出:2
* 解释:1 在数组中,但 2 没有。
* 示例 3:
* 输入:nums = [7,8,9,11,12]
* 输出:1
* 解释:最小的正数 1 没有出现。
*/
public class LackFirstPostiveNumber {
public static void main(String[] args) {
int[] nums = new int[]{3,4,-1,1};
int result = new LackFirstPostiveNumber().firstMissingPositive(nums);
System.out.println(result);
}
public int firstMissingPositive(int[] nums) {
int len = nums.length;
for (int i = 0; i < len; i++) {
// 易错点:为什么使用while而不是if
// 每次交换过来的新元素要一直负责交换到正确的位置上去
while (nums[i] > 0 && nums[i] <= len && nums[nums[i] - 1] != nums[i]) {
// 满足在指定范围内、并且没有放在正确的位置上,才交换
// 例如:数值 3 应该放在索引 2 的位置上
swap(nums, nums[i] - 1, i);
}
}
// [1, -1, 3, 4]
for (int i = 0; i < len; i++) {
if (nums[i] != i + 1) {
return i + 1;
}
}
// 都正确则返回数组长度 + 1
return len + 1;
}
private void swap(int[] nums, int index1, int index2) {
int temp = nums[index1];
nums[index1] = nums[index2];
nums[index2] = temp;
}
}title18 - 矩阵置零
MaxtriSetZero.java
java
package leecode100.title18;
import java.util.Arrays;
/**
* 题目:给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
* https://leetcode.cn/problems/set-matrix-zeroes/?envType=study-plan-v2&envId=top-100-liked
* 输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
* 输出:[[1,0,1],[0,0,0],[1,0,1]]
*
* 输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
* 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
*/
public class MaxtriSetZero {
/**
* 思路:因为使用的是原地算法,所以利用矩阵的第一行和第一列作为标记。
* 1.遍历第一行和第一列查看是否含有0,如果有0,标记一下,后续需要对第一行和第一列进行特殊的处理,置为0。
* 2.从第二行第二列开始遍历,查看是否含有0,如果有0的话,在对应第一行或者第一列的位置上去标记0.
* 3.遍历矩阵,在第一行和第一列有0标记的地方,将除了第一行和第一列的地方设置为0.
* 4.统一处理之前的第一行和第一列的标记情况.
*/
public static void main(String[] args) {
int[][] matrix = new int[][]{{0, 1, 2, 0}, {3, 4, 5, 2}, {1, 3, 1, 5}};
new MaxtriSetZero().setZeroes(matrix);
System.out.println(Arrays.deepToString(matrix));
}
public void setZeroes(int[][] matrix) {
boolean firstRowHasZero = false;
boolean firstColHasZero = false;
// 检查第一行和第一列是否原本有0
for (int i = 0; i < matrix[0].length; i++) {
if (matrix[0][i] == 0) {
firstRowHasZero = true;
break;
}
}
for (int i = 0; i < matrix.length; i++) {
if (matrix[i][0] == 0) {
firstColHasZero = true;
break;
}
}
// 使用第一行和第一列作为标记,标记内部元素的0位置
for (int i = 1; i < matrix.length; i++) {
for (int j = 1; j < matrix[0].length; j++) {
if (matrix[i][j] == 0) {
matrix[0][j] = 0;
matrix[i][0] = 0;
}
}
}
// 根据标记将对应行列置零(除第一行第一列)
for (int i = 1; i < matrix.length; i++) {
for (int j = 1; j < matrix[0].length; j++) {
if (matrix[0][j] == 0 || matrix[i][0] == 0) {
matrix[i][j] = 0;
}
}
}
// 最后处理第一行和第一列
if (firstRowHasZero) {
for (int i = 0; i < matrix[0].length; i++) {
matrix[0][i] = 0;
}
}
if (firstColHasZero) {
for (int i = 0; i < matrix.length; i++) {
matrix[i][0] = 0;
}
}
}
}title19 - 螺旋矩阵
PrintRotateMaxtri.java
java
package leecode100.title19;
import java.util.ArrayList;
import java.util.List;
/*
https://leetcode.cn/problems/spiral-matrix/?envType=study-plan-v2&envId=top-100-liked
题目:给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
*/
public class PrintRotateMaxtri {
/**
* 思路:维护四个边界开始遍历即可。考虑边界情况:如果矩阵为空,直接返回结果。如果矩阵只有一行或者一列的话,特殊处理。
*/
public static void main(String[] args) {
int[][] matrix = new int[][]{{1, 2, 3}};
List<Integer> resultList = new PrintRotateMaxtri().spiralOrder(matrix);
resultList.forEach(System.out::println);
}
public List<Integer> spiralOrder(int[][] matrix) {
if (matrix == null) {
return new ArrayList<>();
}
if (matrix.length == 0) {
return new ArrayList<>();
}
ArrayList<Integer> resultList = new ArrayList<>();
int top = 0;
int left = 0;
int right = matrix[0].length - 1; //列数
int bottom = matrix.length - 1; //行数
while (top <= bottom && left <= right) {
if (top <= bottom) {
for (int i = left; i <= right; i++) {
resultList.add(matrix[top][i]); //从左边向右边开始遍历 遍历top行
}
top++;
}
if (left <= right) {
for (int i = top; i <= bottom; i++) { //从上到下开始遍历 遍历right列
resultList.add(matrix[i][right]);
}
right--;
}
if (top <= bottom) {
for (int i = right; i >= left; i--) { //从右边到左边开始遍历
resultList.add(matrix[bottom][i]);
}
bottom--;
}
if (left <= right) {
for (int i = bottom; i >= top; i--) { //从下到上开始开始遍历
resultList.add(matrix[i][left]);
}
left++;
}
}
return resultList;
}
}title20 - 旋转图像
RotateMatrix.java
java
package leecode100.title20;
import java.util.Arrays;
/**
* 题目:
* 给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
* 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
* 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
* 输出:[[7,4,1],[8,5,2],[9,6,3]]
* <p>
* 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
* 输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
*/
public class RotateMatrix {
/**
* 思路:
* 原来的矩阵:
* 1 2 3
* 4 5 6
* 7 8 9
* 旋转后,变成:
* 7 4 1
* 8 5 2
* 9 6 3
* 你会发现:
* 第一行(1 2 3)变成了最后一列(1 2 3 倒过来,变成 3 2 1)。
* 第二行(4 5 6)变成了倒数第二列(6 5 4)。
* 最后一行的 7 8 9 变成了第一列(7 8 9)。
* 但是我们不能利用另一个矩阵来旋转,怎么做呢?
* 先将矩阵斜着对角互换,然后再左右翻。
*/
public static void main(String[] args) {
int[][] matrix = new int[][]{{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
new RotateMatrix().rotate(matrix);
System.out.println(Arrays.deepToString(matrix));
}
public void rotate(int[][] matrix) {
int rowNum = matrix.length;
int colNum = matrix[0].length;
//对角翻
for (int i = 0; i < rowNum; i++) {
for (int j = i; j < colNum; j++) { //遍历对角矩阵即可
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
//左右翻 matrix[i][j] 和 matrix[i][n-1-j]
for (int i = 0; i < rowNum; i++) {
for (int j = 0; j < colNum / 2; j++) {
int temp = matrix[i][j];
matrix[i][j] = matrix[i][colNum - 1 - j];
matrix[i][colNum - 1 - j] = temp;
}
}
}
}title21 - 搜索二维矩阵 II
SearchTwoDimensionalMatrix.java
java
package leecode100.title21;
/**
* https://leetcode.cn/problems/search-a-2d-matrix-ii/description/?envType=study-plan-v2&envId=top-100-liked
* 题目:编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
* 每行的元素从左到右升序排列。
* 每列的元素从上到下升序排列。
*
* 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
* 输出:true
*
*
* m == matrix.length
* n == matrix[i].length
* 1 <= n, m <= 300
* -109 <= matrix[i][j] <= 109
* 每行的所有元素从左到右升序排列
* 每列的所有元素从上到下升序排列
* -109 <= target <= 109
*/
public class SearchTwoDimensionalMatrix {
/**
* 高效算法:从右上角开始搜索
* 算法思路
* 利用矩阵的有序特性:每行从左到右递增,每列从上到下递增
* 从右上角元素开始搜索,根据比较结果决定移动方向
* 时间复杂度:O(m+n),空间复杂度:O(1)
*
* 核心思想
* 选择右上角作为起点的原因:
* target < num 时,可以排除整列(向左移动)
* target > num 时,可以排除整行(向下移动)
*/
public static void main(String[] args) {
}
public boolean searchMatrix(int[][] matrix, int target) {
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return false;
}
int row = 0;
int col = matrix[0].length - 1;
while (row < matrix.length && col >= 0) {
if (matrix[row][col] == target) {
return true;
} else if (target < matrix[row][col]) {
col--; // 目标值小于矩阵元素,向左移动
} else {
row++; // 目标值大于矩阵元素,向下移动
}
}
return false;
}
}title22 - 相交链表
IntersectingNode.java
java
package leecode100.title22;
import hot100.DataStruct.ListNode;
/**
* https://leetcode.cn/problems/intersection-of-two-linked-lists/?envType=study-plan-v2&envId=top-100-liked
* 相交链表:
* 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
* 链表 A:1 -> 2 -> 3 -> 4 -> 5
* 链表 B:6 -> 4 -> 5
*/
public class IntersectingNode {
/**
* 思路:由于A和B的长度不同,不好比较。
* 可以遍历的时候,如果A遍历完了,可以遍历B。B遍历完了,可以遍历A。
*/
public static void main(String[] args) {
// 创建共享节点:4 -> 5
ListNode common = new ListNode(4, new ListNode(5, null));
// 链表 A: 1 -> 2 -> 3 -> 4 -> 5
ListNode headA = new ListNode(1, new ListNode(2, new ListNode(3, common)));
// 链表 B: 6 -> 4 -> 5
ListNode headB = new ListNode(6, common);
ListNode intersectionNode = new IntersectingNode().getIntersectionNode(headA, headB);
System.out.println(intersectionNode != null ? intersectionNode.val : "null");
}
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null; // 空链表无交点
}
ListNode currentA = headA; //工作结点
ListNode currentB = headB;
while (currentA != currentB) {
if (currentA == null) {
currentA = headB;
} else {
currentA = currentA.next;
}
if (currentB == null) {
currentB = headA;
} else {
currentB = currentB.next;
}
}
return currentA;
}
}title23 - 反转链表
ReverseListNode.java
java
package leecode100.title23;
import hot100.DataStruct.ListNode;
import hot100.DataStruct.utils.ListNodeUtils;
/**
* 反转链表
* 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
* 输入:head = [1,2,3,4,5]
* 输出:[5,4,3,2,1]
*/
public class ReverseListNode {
/***
* 思路:给定一个单链表,例如 1 -> 2 -> 3 -> 4 -> 5,我们需要将其反转为 5 -> 4 -> 3 -> 2 -> 1。输入是链表的头节点,返回反转后的头节点。
* 遍历链表,依次改变每个节点的 next 指针,使其指向前一个节点。
* 为了避免在反转过程中丢失后续节点,需要在每次操作时保存当前节点的下一个节点。
* 同时,需要跟踪前一个节点,以便将当前节点的 next 指针指向它。
* 所以需要三个指针pre current next
* 遍历链表,直到 curr 为空:
* 保存 curr 的下一个节点:next = curr.next。
* 将 curr 的 next 指针指向 prev,实现反转:curr.next = prev。
* 更新 prev 为当前节点:prev = curr。
* 移动 curr 到下一个节点:curr = next。
* 遍历结束后,prev 指向反转后的头节点。
*
*/
public static void main(String[] args) {
ListNode headA = new ListNode(1, new ListNode(2, new ListNode(3, null)));
ListNode listNode = new ReverseListNode().reverseList(headA);
ListNodeUtils.printListNode(listNode);
}
// 1 -> 2
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode current = head;
ListNode next = null;
while (current != null) {
//处理当前的结点
next = current.next;
current.next = pre;
pre = current;
current = next;
}
return pre;
}
}title24 - 回文链表
PalindromeLinkNode.java
java
package leecode100.title24;
import hot100.DataStruct.ListNode;
/**
* 回文链表
* 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
* 输入:head = [1,2,2,1]
* 输出:true
*/
public class PalindromeLinkNode {
/**
* 思路:使用快慢指针找到中心结点,进行反转链表
* 然后从头结点和中心结点之后开始遍历比较,如果值是一样的,是回文链表,如果不是一样的,就不是回文链表。
*/
public static void main(String[] args) {
ListNode headA = new ListNode(1, new ListNode(2, new ListNode(2, new ListNode(1, null))));
System.out.println(headA.val);
boolean palindrome = new PalindromeLinkNode().isPalindrome(headA);
System.out.println(palindrome);
}
// 1,2,2,1
public boolean isPalindrome(ListNode head) {
ListNode slow = head;
ListNode fast = head;
// 只允许fast.next.next为null
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
ListNode pre = reverseListNode(slow);
ListNode work = head;
//易错点: 反转后,while循环直到pre为null
while (pre != null) {
if (pre.val != work.val) return false;
pre = pre.next;
work = work.next;
}
return true;
}
public ListNode reverseListNode(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while (cur != null) {
ListNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
}title25 - 环形链表
CycleLinkNode.java
java
package leecode100.title25;
import hot100.DataStruct.ListNode;
/**
* 环形链表:
* 给你一个链表的头节点 head ,判断链表中是否有环。
* 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。
* 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。
* 注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
* 如果链表中存在环 ,则返回 true 。 否则,返回 false。
* <p>
* 输入:head = [3,2,0,-4], pos = 1
* 输出:true
* 解释:链表中有一个环,其尾部连接到第二个节点。
*/
public class CycleLinkNode {
/**
* 思路:利用快慢指针,如果快指针追上了慢指针,代表存在环形链表,如果没有追上fast为null的话,说明没有环.
*/
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
slow = slow.next; // 慢指针走一步
fast = fast.next.next; // 快指针走两步
if (fast == slow) {
return true;
}
}
return false;
}
}title26 - 环形链表 II
CycleLinkNode2.java
java
package leecode100.title26;
import hot100.DataStruct.ListNode;
/**
* 环形链表2:
* 给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
* 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。
* 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。
* 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
* <p>
* 输入:head = [3,2,0,-4], pos = 1
* 输出:返回索引为 1 的链表节点
* 解释:链表中有一个环,其尾部连接到第二个节点。
*/
public class CycleLinkNode2 {
/**
* 快指针是慢指针的两倍 如果链表存在环的话,那么快指针一定会相遇到慢指针。快指针的速度是慢指针速度的2倍。
* 假设起点到环的入口的距离假设为x,入口到相遇点为y,相遇点到入口的距离为z。
* 相遇点时,慢指针走过的距离为 x+y,快指针走过的距离为 x+y+z+y
* 因为快指针的速度是慢指针的2倍,所以有 2(x+y) = x+y+z+y,可得 x = z
*/
public ListNode detectCycle(ListNode head) {
ListNode slow = head;
ListNode fast = head;
// 如果无环,fast走到链表末尾结束循环
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
//有环,distance(相遇点到环交点) = distance(head到环交点)
if (slow == fast) {
ListNode index1 = head;
ListNode index2 = fast;
while (index1 != index2) {
index1 = index1.next;
index2 = index2.next;
}
return index1;
}
}
return null;
}
}title27 - 合并两个有序链表
MergeTwoListNode.java
java
package leecode100.title27;
import hot100.DataStruct.ListNode;
/**
* 题目:将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
* 输入:l1 = [1,2,4], l2 = [1,3,4]
* 输出:[1,1,2,3,4,4]
*/
public class MergeTwoListNode {
/**
* 思路:
* 1.初始化:
* -创建一个虚拟头节点(dummy node)作为新链表的起点,方便处理合并后的链表。
* -使用一个指针(current)来构建新链表,初始指向虚拟头节点。
* 2.比较与拼接:
* -同时遍历 list1 和 list2,比较当前节点的值:
* -如果 list1 的节点值小于等于 list2 的节点值,选择 list1 的节点,将其接到新链表的 current 指针后,并移动 list1 指针。
* -否则,选择 list2 的节点,接到 current 指针后,并移动 list2 指针。
* 3.每次选择节点后,移动 current 指针到新拼接的节点。
* 处理剩余节点:
* 当其中一个链表遍历完(即为空),将另一个链表的剩余部分直接接到新链表的末尾。
* 4.返回结果:
* 返回虚拟头节点的下一个节点作为新链表的头节点。
*/
public static void main(String[] args) {
}
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode dummy = new ListNode(0);
ListNode current = dummy;
while (list1 != null && list2 != null) {
if (list1.val >= list2.val) {
current.next = list2;
list2 = list2.next;
} else {
current.next = list1;
list1 = list1.next;
}
current = current.next;
}
current.next = list1 != null ? list1 : list2;
return dummy.next;
}
}title28 - 两数相加
TwoNumberAdd.java
java
package leecode100.title28;
import hot100.DataStruct.ListNode;
/**
* 两数相加:
* 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
* 请你将两个数相加,并以相同形式返回一个表示和的链表。
* 你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
* 输入:l1 = [2,4,3], l2 = [5,6,4]
* 输出:[7,0,8]
* 解释:342 + 465 = 807.
*/
public class TwoNumberAdd {
/**
* 思路:两数相加 当前为就是sum%10 进位就是sum//10 sum为两数相加再加上进位carry
*/
public static void main(String[] args) {
}
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode current = dummy;
int carry = 0;
while (l1 != null && l2 != null) {
int sum = l1.val + l2.val + carry;
int currentVal = sum % 10; //当前值
carry = sum / 10; //进位
current.next = new ListNode(currentVal);
current = current.next;
l1 = l1.next;
l2 = l2.next;
}
while (l2!=null) {
int sum = l2.val + carry;
int currentVal = sum % 10; //当前值
carry = sum / 10; //进位
current.next = new ListNode(currentVal);
current = current.next;
l2 = l2.next;
}
while (l1!=null){
int sum = l1.val + carry;
int currentVal = sum % 10; //当前值
carry = sum / 10; //进位
current.next = new ListNode(currentVal);
current = current.next;
l1 = l1.next;
}
if (carry == 1) { //漏掉了进位
current.next = new ListNode(1);
}
return dummy.next;
}
}title29 - 删除链表的倒数第 N 个结点
DeleteFromEndN.java
java
package leecode100.title29;
import hot100.DataStruct.ListNode;
import static hot100.DataStruct.utils.ListNodeUtils.printListNode;
/**
* 题目:
* 删除链表的倒数第 N 个结点
* 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
* 输入:head = [1,2,3,4,5], n = 2
* 输出:[1,2,3,5]
*/
public class DeleteFromEndN {
/**
* 思路:求出链表的长度,然后长度减去倒数的数,就是遍历到的结点下一个结点就是删除的及节点
* 1 2 3 4 5
*/
public static void main(String[] args) {
ListNode head = new ListNode(1, new ListNode(2, new ListNode(3, new ListNode(4, new ListNode(5, null)))));
// ListNode head = new ListNode(1);
ListNode listNode = new DeleteFromEndN().removeNthFromEnd(head, 2);
printListNode(listNode);
}
public ListNode removeNthFromEnd(ListNode head, int n) {
int length = length(head);
int needLength = length - n;
ListNode current = head;
if (needLength == 0) {
return head.next; //考虑特殊情况
}
//前段只保留needLength,所以指针从head只需移动needLength -1,就能指向第needLength个元素
int cnt = needLength -1;
while (cnt-- > 0){
current = current.next;
}
// for (int i = 0; i < needLength - 1; i++) {
// current = current.next;
// }
current.next = current.next.next;
return head;
}
public int length(ListNode head) {
ListNode current = head;
int length = 0;
while (current != null) {
current = current.next;
length++;
}
return length;
}
}title30 - 两两交换链表中的节点
TwoSwapLinkNode.java
java
package leecode100.title30;
import hot100.DataStruct.ListNode;
import hot100.DataStruct.utils.ListNodeUtils;
/**
* 题目:
* 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
*/
public class TwoSwapLinkNode {
/**
* 思路:
* 具体步骤(以 1->2->3->4 为例)
* <p>
* 初始状态:
* <p>
* 链表是:dummy->1->2->3->4。
* 裁判(dummy)先指向 1,1 指向 2,2 指向 3,3 指向 4。
* 我们用两个指针:prev 指向裁判(dummy),cur 指向 1。
* <p>
* <p>
* 第一对交换(1 和 2):
* <p>
* 现在要让 1 和 2 换位置,目标是变成 dummy->2->1->3->4。
* 具体操作:
* <p>
* 先记住 2 的下一个节点(3),免得等会儿找不到。
* 让 1 的手(next 指针)指向 3(跳过 2)。
* 让 2 的手指向 1(2 变成前面的)。
* 让dummy的手指向 2(2 变成新头)。
* <p>
* <p>
* 结果:dummy->2->1->3->4。
* 更新指针:prev 移到 1,cur 移到 3(准备下一对)。
* <p>
* <p>
* 第二对交换(3 和 4):
* <p>
* 现在处理 3 和 4,目标是变成 dummy->2->1->4->3。
* 同样操作:
* <p>
* 记住 4 的下一个节点(这里是 null,没下一个了)。
* 让 3 的手指向 null(跳过 4)。
* 让 4 的手指向 3。
* 让 1 的手(因为 1 是现在的 prev)指向 4。
* <p>
* <p>
* 结果:dummy->2->1->4->3。
* 此时 cur 移到 null,说明没节点可换了,结束。
* <p>
* <p>
* 返回结果:
* <p>
* 裁判(dummy)的 next 指向 2,所以返回 2 作为新链表的头。
* 最终链表:2->1->4->3。
*/
public static void main(String[] args) {
ListNode head = new ListNode(1, new ListNode(2, new ListNode(3, new ListNode(4, null))));
ListNode listNode = new TwoSwapLinkNode().swapPairs(head);
ListNodeUtils.printListNode(listNode);
}
public ListNode swapPairs(ListNode head) {
ListNode dumpy = new ListNode(0);
dumpy.next = head;
ListNode current = head;
ListNode pre = dumpy;
while (current != null && current.next != null) { //1234
ListNode nextnext = current.next.next; //记录节点
ListNode next = current.next; //记录节点
current.next = nextnext; //1->3 213
next.next = current; //2->1
pre.next = next; //更新变化完之后,pre连接下一个节点
pre = current; //更新pre节点
current = current.next; //移动current节点
}
return dumpy.next;
}
}title31 - K 个一组翻转链表
K_ReverseLinkNode.java
java
package leecode100.title31;
import hot100.DataStruct.ListNode;
import hot100.DataStruct.utils.ListNodeUtils;
/**
* 题目:K个一组翻转链表
* 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
* k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
* 你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
* 输入:head = [1,2,3,4,5], k = 2
* 输出:[2,1,4,3,5]
* 输入:head = [1,2,3,4,5], k = 3
* 输出:[3,2,1,4,5]
*/
public class K_ReverseLinkNode {
/**
* 思路:上一题两两翻转的扩展版
* 维护几个指针prev end start 遍历找到待翻转组的前一个节点以及当前翻转组的头节点
* 将头节点到待翻转组的前一个节点进行翻转 依次循环直到end的下一个节点为null,或者不足k个节点
*/
public static void main(String[] args) {
//写出测试用例
ListNode head = new ListNode(1, new ListNode(2, new ListNode(3, new ListNode(4, new ListNode(5, null)))));
ListNode listNode = new K_ReverseLinkNode().reverseKGroup(head, 2);
ListNodeUtils.printListNode(listNode);
}
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dumpy = new ListNode(0);
dumpy.next = head;
ListNode prev = dumpy;
ListNode end = dumpy;
while (end.next != null) {
for (int i = 0; i < k && end != null; i++) {
end = end.next;
}
//end为翻转组的前一个节点
if (end == null) { //如果不足k的节点,直接跳出循环
break;
}
ListNode next = end.next; //待翻转区域的头结点
end.next = null; //断链
ListNode start = prev.next; //开始翻转的头结点
prev.next = null;
//开始链表的翻转
//3,2,1,4,5,6
prev.next = reverseListNode(start);
start.next = next; //连接待翻转区域的头结点
prev = start; //prev = 1
end = start; // end = 1
}
return dumpy.next;
}
//进行链表的翻转 123
private ListNode reverseListNode(ListNode start) {
ListNode prev = null;
ListNode curr = start;
ListNode next = null;
while (curr != null) {
next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev;
}
}title32 - 复制带随机指针的链表
RandomLinkNodeCopy.java
java
package leecode100.title32;
import hot100.DataStruct.Node;
import hot100.DataStruct.utils.ListNodeUtils;
/**
* 题目:
* 给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
* 构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。
* 新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
* 例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
* 返回复制链表的头节点。
* 用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
* val:一个表示 Node.val 的整数。
* random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
* 你的代码 只 接受原链表的头节点 head 作为传入参数。
* 输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
* 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
*/
public class RandomLinkNodeCopy {
/**
* 思路:先复制链表的节点的next指针,原来是A -> B -> C
* 复制完毕之后变为A -> A' -> B -> B' -> C -> C'
* 然后复制random指针,比如A的random指向C,那么刚好A'指向C的next的后一个C'
* 然后剔除原来的ABC那个节点即可。
*/
public static void main(String[] args) {
Node node1 = new Node(1);
Node node2 = new Node(2);
Node node3 = new Node(3);
node1.next = node2;
node2.next = node3;
node1.random = node3;
node2.random = node1;
node3.random = node2;
Node node = new RandomLinkNodeCopy().copyRandomList(node1);
ListNodeUtils.printNode(node);
}
public Node copyRandomList(Node head) {
if (head == null) {
return null;
}
//步骤1:先复制链表的节点的next指针
Node curr = head;
while (curr != null) {
Node next = curr.next;
Node newNode = new Node(curr.val);
curr.next = newNode;
newNode.next = next;
curr = next;
}
//步骤2:然后复制random指针
Node work = head;
while (work != null && work.next != null) {
Node nextnext = work.next.next;
if (work.random != null) {
work.next.random = work.random.next;
} else {
work.next.random = null;
}
work = nextnext;
}
//步骤3:然后剔除原来的节点 A -> A' -> B -> B' -> C -> C'
Node dummy = new Node(0);
dummy.next = head.next; // 副本链表的头节点
Node original = head;
while (original != null) {
Node copy = original.next;
original.next = original.next.next; // 恢复原链表
if (copy.next != null) {
copy.next = copy.next.next; // 连接副本链表
}
original = original.next; // 移动到下一个原节点
}
return dummy.next;
}
}title33 - 排序链表
SortLinkNode.java
java
package leecode100.title33;
import hot100.DataStruct.ListNode;
import hot100.DataStruct.utils.ListNodeUtils;
import java.util.Arrays;
/**
* 题目:排序链表
* 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
*
* 示例 1:
* 输入:head = [4,2,1,3]
* 输出:[1,2,3,4]
*
* 示例 2:
* 输入:head = [-1,5,3,4,0]
* 输出:[-1,0,3,4,5]
*
* 示例 3:
* 输入:head = []
* 输出:[]
*
* 提示:
* 链表中节点的数目范围是 [0, 5 * 10^4]
* -10^5 <= Node.val <= 10^5
*
* 进阶:你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
*/
public class SortLinkNode {
/**
* 思路:将链表节点值提取到数组中,排序后重新构建链表
* 时间复杂度:O(n log n)
* 空间复杂度:O(n)
*
* 注:这不是最优解法,最优解应使用归并排序实现 O(1) 空间复杂度
*/
public static void main(String[] args) {
// 测试用例
ListNode head = new ListNode(4, new ListNode(2, new ListNode(1, new ListNode(3))));
SortLinkNode solution = new SortLinkNode();
ListNode sortedHead = solution.sortList(head);
ListNodeUtils.printListNode(sortedHead); // 应输出 1->2->3->4
}
/**
* 对链表进行排序
* @param head 链表头节点
* @return 排序后的链表头节点
*/
public ListNode sortList(ListNode head) {
// 边界条件处理
if (head == null || head.next == null) {
return head;
}
// 获取链表长度
int length = getLength(head);
// 提取节点值到数组
int[] nums = new int[length];
ListNode work = head;
for (int i = 0; i < length; i++) {
nums[i] = work.val;
work = work.next;
}
// 数组排序
Arrays.sort(nums);
// 重新构建链表
ListNode dummy = new ListNode(0);
ListNode current = dummy;
for (int i = 0; i < nums.length; i++) {
current.next = new ListNode(nums[i]);
current = current.next;
}
return dummy.next;
}
/**
* 获取链表长度
* @param head 链表头节点
* @return 链表长度
*/
public int getLength(ListNode head) {
ListNode current = head;
int length = 0;
while (current != null) {
current = current.next;
length++;
}
return length;
}
}title34 - 合并 K 个升序链表
MergeKListNode.java
java
package leecode100.title34;
import hot100.DataStruct.ListNode;
import hot100.DataStruct.utils.ListNodeUtils;
import java.util.ArrayList;
import java.util.Arrays;
/**
* 题目:合并 K 个升序链表
* 给你一个链表数组,每个链表都已经按升序排列。
* 请你将所有链表合并到一个升序链表中,返回合并后的链表。
* 示例 1:
* 输入:lists = [[1,4,5],[1,3,4],[2,6]]
* 输出:[1,1,2,3,4,4,5,6]
* 解释:链表数组如下:
* [1->4->5,1->3->4,2->6]
* 将它们合并到一个有序链表中得到。
* 1->1->2->3->4->4->5->6
*/
public class MergeKListNode {
/**
* 思路:将链表中的数据放入到数组之中,然后进行排序,排完序之后再合并成链表
*/
public static void main(String[] args) {
ListNode head = new ListNode(1,new ListNode(4,new ListNode(5)));
ListNode head1 = new ListNode(1,new ListNode(3,new ListNode(4)));
ListNode head2 = new ListNode(2,new ListNode(6));
ArrayList<ListNode> lists = new ArrayList<>();
lists.add(head);
lists.add(head1);
lists.add(head2);
ListNode[] listNodes = lists.toArray(new ListNode[0]);
ListNode listNode = new MergeKListNode().mergeKLists(listNodes);
ListNodeUtils.printListNode(listNode);
}
/**
* 合并K个升序链表
* @param lists 链表数组,每个链表已按升序排列
* @return 合并后的升序链表
*/
public ListNode mergeKLists(ListNode[] lists) {
// 边界条件检查
if (lists == null || lists.length == 0) {
return null;
}
// 统计所有链表中的节点总数
int length = 0;
for (int i = 0; i < lists.length; i++) {
ListNode currentNode = lists[i];
while (currentNode != null) {
currentNode = currentNode.next;
length++;
}
}
// 如果没有节点,直接返回null
if (length == 0) {
return null;
}
// 将所有节点值收集到数组中
int[] nums = new int[length];
length = 0;
for (int i = 0; i < lists.length; i++) {
ListNode currentNode = lists[i];
while (currentNode != null) {
nums[length] = currentNode.val;
currentNode = currentNode.next;
length++;
}
}
// 对数组进行排序
Arrays.sort(nums);
// 根据排序后的数组构建新的链表
ListNode dummy = new ListNode(0); // 虚拟头节点,简化链表操作
ListNode current = dummy;
for (int i = 0; i < nums.length; i++) {
current.next = new ListNode(nums[i]); // 创建新节点并连接
current = current.next; // 移动到下一个节点
}
return dummy.next; // 返回真正的头节点
}
}title35 - LRU 缓存
LRUCacheDemo.java
java
package leecode100.title35;
import java.util.LinkedHashMap;
/**
* 题目:请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
* 实现 LRUCache 类:
* LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
* int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
* void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。
* 如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
* 函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
*/
public class LRUCacheDemo {
/**
* 思路:利用LinkedHashMap,底层采用双向链表+哈希表去实现的
* 删除再插入 就可以改变原有链表数据的顺序
*/
public static void main(String[] args) {
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
System.out.println("get: " + lRUCache.get(1)); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
System.out.println("get: " + lRUCache.get(2)); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
System.out.println("get: " + lRUCache.get(1)); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
System.out.println("get: " + lRUCache.get(3)); // 返回 3
System.out.println("get: " + lRUCache.get(4)); // 返回 4
}
}
class LRUCache {
LinkedHashMap<Integer, Integer> cache = new LinkedHashMap<>();
int cap;
public LRUCache(int capacity) {
this.cap = capacity;
}
//如果 key 存在,返回对应的 value,并标记为“最近使用”;否则返回 -1。
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
makeRecently(key);
return cache.get(key);
}
//如果 key 存在,更新 value 并标记为“最近使用”;如果不存在,插入新 key-value 对。如果缓存超过容量,移除最久未使用的项。
public void put(int key, int value) {
// 先移除可能存在的旧值(如果存在则更新,不存在则无影响)
if (cache.containsKey(key)) {
cache.put(key, value);
makeRecently(key);
return;
}
// 检查是否需要淘汰最老元素
if (cache.size() >= this.cap) {
int oldKey = cache.keySet().iterator().next();
cache.remove(oldKey);
}
// 插入新值
cache.put(key, value);
}
private void makeRecently(int key) {
Integer val = cache.get(key);
cache.remove(key); //移除老的值
cache.put(key,val); //放入新的值
}
}title36 - 二叉树的中序遍历
TreePostOrder.java
java
package leecode100.title36;
import hot100.DataStruct.TreeNode;
import java.util.ArrayList;
import java.util.List;
/***
* 题目:二叉树的中序遍历
* 给定一个二叉树的根节点 root ,返回它的中序遍历 。
*/
public class TreePostOrder {
/**
* 思路:中序遍历就是左根右遍历 先处理左子树 然后处理根节点 最后处理右子树
*/
public static void main(String[] args) {
}
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> result = new ArrayList<>();
inorder(root, result);
return result;
}
private void inorder(TreeNode root, ArrayList<Integer> result) {
if (root == null) {
return;
}
inorder(root.left, result);
result.add(root.val);
inorder(root.right, result);
}
}title37 - 二叉树的最大深度
TreeMaxDeep.java
java
package leecode100.title37;
import hot100.DataStruct.TreeNode;
import hot100.DataStruct.utils.TreeUtils;
/**
* 题目:树的最大深度
* 给定一个二叉树 root ,返回其最大深度。
* 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
*/
public class TreeMaxDeep {
/**
* 思路:递归解决即可 当前节点的最大深度就是Max(左子树的深度或者右子树的深度)+1就是树的最大深度
*/
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.right = new TreeNode(5);
TreeUtils.printTree(root);
int result = new TreeMaxDeep().maxDepth(root);
System.out.println(result);
}
public int maxDepth(TreeNode root) {
if (root == null) {
return 0;
} else {
int leftdeep = maxDepth(root.left);
int rightdeep = maxDepth(root.right);
return Math.max(leftdeep, rightdeep) + 1;
}
}
}title38 - 翻转二叉树
ReverseTree.java
java
package leecode100.title38;
import hot100.DataStruct.TreeNode;
import hot100.DataStruct.utils.TreeUtils;
/**
* https://leetcode.cn/problems/invert-binary-tree/description/?envType=study-plan-v2&envId=top-100-liked
* 翻转二叉树
* 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
*/
public class ReverseTree {
/**
* 思路:最大的根节点不动,让左子树变为右子树 右子树变为左子树
*/
public static void main(String[] args) {
// 2
// 1 3
TreeNode root = new TreeNode(2);
root.left = new TreeNode(1);
root.right = new TreeNode(3);
TreeNode treeNode = new ReverseTree().invertTree(root);
TreeUtils.printTree(treeNode);
}
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
//交换左右子树
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTree(root.left);
invertTree(root.right);
return root;
}
}title39 - 对称二叉树
SymmetryTree.java
java
package leecode100.title39;
import hot100.DataStruct.TreeNode;
/**
* 题目:对称二叉树
* 给你一个二叉树的根节点,检查它是否轴对称。
*
* 示例 1:
* 输入:root = [1,2,2,3,4,4,3]
* 输出:true
*
* 示例 2:
* 输入:root = [1,2,2,null,3,null,3]
* 输出:false
*
* 提示:
* 树中节点数目在范围 [1, 1000] 内
* -100 <= Node.val <= 100
*
* 进阶:你可以运用递归和迭代两种方法解决这个问题吗?
*/
public class SymmetryTree {
/**
* 思路:对称镜像的定义是左子树的左节点等于右子树的右节点,左子树的右节点等于右子树的左节点
* 对于两棵子树(假设为 left 和 right),它们镜像对称需要满足:
* 1. 两棵子树的根节点值相等。
* 2. left 的左子树与 right 的右子树镜像对称。
* 3. left 的右子树与 right 的左子树镜像对称。
* 如果任一条件不满足(例如一个节点为空而另一个不为空,或者值不相等),则不对称。
*/
public static void main(String[] args) {
// 测试用例1: 对称二叉树
// TreeNode root1 = new TreeNode(1);
// root1.left = new TreeNode(2, new TreeNode(3), new TreeNode(4));
// root1.right = new TreeNode(2, new TreeNode(4), new TreeNode(3));
// System.out.println(new SymmetryTree().isSymmetric(root1)); // 应输出 true
// 测试用例2: 非对称二叉树
TreeNode root2 = new TreeNode(1);
root2.left = new TreeNode(2, null, new TreeNode(3));
root2.right = new TreeNode(2, null, new TreeNode(3));
System.out.println(new SymmetryTree().isSymmetric(root2)); // 应输出 false
}
/**
* 检查二叉树是否对称
* @param root 二叉树根节点
* @return 是否对称
*/
public boolean isSymmetric(TreeNode root) {
if (root == null) {
return true;
}
return Symmetric(root.left, root.right);
}
/**
* 递归的判断左右子树是否是镜像的
* @param left 左子树根节点
* @param right 右子树根节点
* @return 是否镜像对称
*/
private boolean Symmetric(TreeNode left, TreeNode right) {
// 都为空则对称
if (left == null && right == null) {
return true;
}
// 一个为空另一个不为空则不对称
if (left == null || right == null) {
return false;
}
// 值不相等则不对称
if (left.val != right.val) {
return false;
}
// 递归检查:外侧对称且内侧对称
return Symmetric(left.right, right.left) && Symmetric(left.left, right.right);
}
}title40 - 二叉树的直径
DiameterTree.java
java
package leecode100.title40;
import hot100.DataStruct.TreeNode;
/**
* 题目:二叉树的直径
* 给你一棵二叉树的根节点,返回该树的 直径 。
* 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
* 两节点之间路径的 长度 由它们之间边数表示。
*/
public class DiameterTree {
/**
* 思路:最大直径是左边的最大深度加上右边的最大深度,并且维护一个全局变量最大直径
* 从根节点开始,递归遍历每个节点。
* 对于每个节点:
* 1.计算左子树和右子树的深度。
* 2.更新全局最大直径(左深度 + 右深度)。
* 3.返回当前子树的深度(max(左深度, 右深度) + 1)供上层节点使用。
*/
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.right = new TreeNode(5);
int result = new DiameterTree().diameterOfBinaryTree(root);
System.out.println(result);
}
public static int diameter = 0;
public int diameterOfBinaryTree(TreeNode root) {
getDiameter(root);
return diameter;
}
private int getDiameter(TreeNode root) {
if (root == null) {
return 0;
} else {
int leftdeep = getDiameter(root.left);
int rightdeep = getDiameter(root.right);
diameter = Math.max(diameter, leftdeep + rightdeep); //leftdeep + rightdeep 表示以当前节点为路径顶点的路径长度。
return Math.max(leftdeep, rightdeep) + 1; //表示当前子树的深度。
}
}
}title41 - 二叉树的层序遍历
LeverOrderTree.java
java
package leecode100.title41;
import hot100.DataStruct.TreeNode;
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
/**
* 题目:二叉树的层序遍历
* 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
*
* 示例 1:
* 输入:root = [3,9,20,null,null,15,7]
* 输出:[[3],[9,20],[15,7]]
*
* 示例 2:
* 输入:root = [1]
* 输出:[[1]]
*
* 示例 3:
* 输入:root = []
* 输出:[]
*
* 提示:
* 树中节点数目在范围 [0, 2000] 内
* -1000 <= Node.val <= 1000
*/
public class LeverOrderTree {
/**
* 使用队列实现二叉树的层序遍历
* 思路:利用BFS广度优先搜索,按层处理节点
* 1. 将根节点加入队列
* 2. 每次处理当前层的所有节点
* 3. 将下一层节点加入队列
* 4. 重复直到队列为空
*/
public static void main(String[] args) {
// 测试用例
TreeNode root = new TreeNode(3);
root.left = new TreeNode(9);
root.right = new TreeNode(20);
root.right.left = new TreeNode(15);
root.right.right = new TreeNode(7);
LeverOrderTree solution = new LeverOrderTree();
List<List<Integer>> result = solution.levelOrder(root);
System.out.println(result); // 应输出 [[3],[9,20],[15,7]]
}
/**
* 二叉树层序遍历
* @param root 二叉树根节点
* @return 按层分组的节点值列表
*/
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> results = new ArrayList<>();
if (root == null) {
return results;
}
Queue<TreeNode> queue = new ArrayDeque<>();
queue.offer(root);
while (!queue.isEmpty()) {
int levelSize = queue.size(); // 当前层的节点数
List<Integer> currentLevel = new ArrayList<>();
// 处理当前层的所有节点
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
currentLevel.add(node.val);
// 将下一层节点加入队列
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
results.add(currentLevel);
}
return results;
}
}title42 - 将有序数组转换为二叉搜索树
OrderedNumberToOrderedTree.java
java
package leecode100.title42;
import hot100.DataStruct.TreeNode;
/**
* 题目:将有序数组转换为二叉搜索树
* 给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。
*
* 示例 1:
* 输入:nums = [-10,-3,0,5,9]
* 输出:[0,-3,9,-10,null,5]
*
* 示例 2:
* 输入:nums = [1,3]
* 输出:[3,1]
*
* 提示:
* 1 <= nums.length <= 10^4
* -10^4 <= nums[i] <= 10^4
* nums 按 严格递增 顺序排列
*/
public class OrderedNumberToOrderedTree {
/**
* 思路:使用递归分治法构造平衡二叉搜索树
* 1. 选择数组中间元素作为根节点保证平衡性
* 2. 递归构造左子树(左半部分数组)
* 3. 递归构造右子树(右半部分数组)
* 4. 利用BST性质:左子树所有节点 < 根节点 < 右子树所有节点
*/
public static void main(String[] args) {
// 测试用例
int[] nums1 = {-10, -3, 0, 5, 9};
TreeNode root1 = new OrderedNumberToOrderedTree().sortedArrayToBST(nums1);
// 预期输出: 一个有效的平衡BST结构
int[] nums2 = {1, 3};
TreeNode root2 = new OrderedNumberToOrderedTree().sortedArrayToBST(nums2);
// 预期输出: 一个有效的平衡BST结构
}
/**
* 将有序数组转换为平衡二叉搜索树
* @param nums 已排序的整数数组
* @return 平衡二叉搜索树的根节点
*/
public TreeNode sortedArrayToBST(int[] nums) {
if (nums == null || nums.length == 0) {
return null;
}
return buildBST(0, nums.length - 1, nums);
}
/**
* 递归构建平衡BST
* @param left 左边界
* @param right 右边界
* @param nums 数组
* @return 子树根节点
*/
private TreeNode buildBST(int left, int right, int[] nums) {
// 递归终止条件
if (left > right) {
return null;
}
// 选择中间元素作为根节点
int mid = left + (right - left) / 2;
TreeNode root = new TreeNode(nums[mid]);
// 递归构造左右子树
root.left = buildBST(left, mid - 1, nums);
root.right = buildBST(mid + 1, right, nums);
return root;
}
}title43 - 验证二叉搜索树
VerfiySearchTree.java
java
package leecode100.title43;
import hot100.DataStruct.TreeNode;
import java.util.ArrayList;
/**
* 验证二叉搜索树
* 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
* 有效二叉搜索树定义如下:
* 节点的左子树只包含 严格小于 当前节点的数。
* 节点的右子树只包含 严格大于 当前节点的数。
* 所有左子树和右子树自身必须也是二叉搜索树。
*/
public class VerfiySearchTree {
/**
* 思路:借助空间数组保存中序遍历的二叉树的顺序,如果是递增的数组就是二叉搜索树,如果不是的话就不是二叉搜索树。
*/
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
root.left = new TreeNode(2);
root.right = new TreeNode(3);
root.left.left = new TreeNode(4);
root.left.right = new TreeNode(5);
}
public boolean isValidBST(TreeNode root) {
ArrayList<Integer> result = new ArrayList<>();
postOrder(result, root);
Integer[] nums = result.toArray(new Integer[0]);
for (int i = 1; i < nums.length; i++) {
if (nums[i] <= nums[i - 1]) {
return false;
}
}
return true;
}
private void postOrder(ArrayList<Integer> result, TreeNode root) {
if (root == null) {
return;
}
postOrder(result, root.left);
result.add(root.val);
postOrder(result, root.right);
}
}title44 - 二叉搜索树中第 K 小的元素
SearchKNum.java
java
package leecode100.title44;
import hot100.DataStruct.TreeNode;
/**
* 题目:
* 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)
*/
public class SearchKNum {
/**
* 思路:由于是二叉搜索树,所以对于中序排序就是递增的,用一个计数器记录节点序号,找到第k个节点时返回其值。
*/
public static void main(String[] args) {
}
public static int count = 0;
public static int result = 0;
public int kthSmallest(TreeNode root, int k) {
count = 0; // 初始化计数器
result = 0; // 初始化结果
postOrder(root, k);
return result;
}
private void postOrder(TreeNode root, int k) {
if (root == null) {
return;
}
postOrder(root.left, k);
count++;
if (count == k) {
result = root.val;
return;
}
postOrder(root.right, k);
}
}title45 - 二叉树的右视图
TreeRightView.java
java
package leecode100.title45;
import hot100.DataStruct.TreeNode;
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.List;
/**
* 题目:二叉树的右视图
* 给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节
*/
public class TreeRightView {
/**
* 思路:层序遍历 记录最后一个节点的值即可。
*/
public static void main(String[] args) {
}
public List<Integer> rightSideView(TreeNode root) {
ArrayList<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
ArrayDeque<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode treeNode = queue.poll();
if (treeNode != null) {
if (i == size - 1) {
result.add(treeNode.val);
}
if (treeNode.left != null) {
queue.add(treeNode.left);
}
if (treeNode.right != null) {
queue.add(treeNode.right);
}
}
}
}
return result;
}
}title46 - 二叉树展开为链表
TreeNodeToLinkedNode.java
java
package leecode100.title46;
import hot100.DataStruct.TreeNode;
/**
* 题目:二叉树展开为链表
* 给你二叉树的根结点 root ,请你将它展开为一个单链表:
* 展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
* 展开后的单链表应该与二叉树 先序遍历 顺序相同。
*/
public class TreeNodeToLinkedNode {
/**
* 思路:后续遍历先处理左右子树,将左子树或者右子树展开之后,再处理根节点,根节点连接左子树或者右子树
* 后序遍历先处理子树,确保左右子树已经是链表形式,再处理根节点时只需简单拼接。
* 先序遍历处理根时,子树还没展开,连接会出错。
*/
public static void main(String[] args) {
}
public void flatten(TreeNode root) {
if (root == null) {
return;
}
flatten(root.left);
flatten(root.right);
//保存最右边的节点
TreeNode rightTemp = root.right;
root.right = root.left;
root.left = null;
TreeNode current = root;
while (current.right != null) {
current = current.right;
}
current.right = rightTemp;
}
}title47 - 从前序与中序遍历序列构造二叉树
CreateTreeFromPreAndPostOrder.java
java
package leecode100.title47;
import hot100.DataStruct.TreeNode;
/**
* 题目:从前序与中序遍历序列构造二叉树
* 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
* 输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
* 输出: [3,9,20,null,null,15,7]
*/
public class CreateTreeFromPreAndPostOrder {
/**
* 思路:先确定根节点,刚开始根节点是preorder中的第一个节点
* 划分左右子树,去中序遍历中寻找到这个节点,左边是左子树,右边是右子树。
* 递归的构造子树,根据左子树节点数量,从前序遍历中划分出左子树的前序序列和右子树的前序序列
* 递归地对左子树和右子树重复上述过程:
* 左子树:用左子树的前序和中序序列构造左子树。
* 右子树:用右子树的前序和中序序列构造右子树。
*/
public static void main(String[] args) {
int[] preorder = new int[]{3, 9, 20, 15, 7};
int[] inorder = new int[]{9, 3, 15, 20, 7};
new CreateTreeFromPreAndPostOrder().buildTree(preorder, inorder);
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
return buildTreeHelper(preorder, inorder, 0, preorder.length - 1, 0, preorder.length - 1);
}
private TreeNode buildTreeHelper(int[] preorder, int[] inorder, int prestart, int preend, int instart, int inend) {
if (prestart > preend || instart > inend) return null;
int rootval = preorder[prestart];
TreeNode root = new TreeNode(rootval);
int i;
for (i = 0; i < inorder.length; i++) {
if (rootval == inorder[i]) {
break;
}
}
//左子树的长度
int llen = i - instart;
//递归构造左右子树
root.left = buildTreeHelper(preorder, inorder, prestart + 1, prestart + llen, instart, i - 1);
root.right = buildTreeHelper(preorder, inorder, prestart + llen + 1, preend, i + 1, inend);
return root;
}
}title48 - 路径总和 III
SumOfRoad.java
java
package leecode100.title48;
import hot100.DataStruct.TreeNode;
import java.util.HashMap;
import java.util.Map;
/**
* 题目:路径总和 III
* 给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
* 路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
* <p>
* 输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
* 输出:3
* 解释:和等于 8 的路径有 3 条,如图所示。
*/
public class SumOfRoad {
/**
* 思路:利用前缀和解决即可。通过dfs算法递归遍历+回溯 通过查看当前节点是否存在前缀和prevSum
*/
public static void main(String[] args) {
TreeNode root = new TreeNode(1);
root.left = new TreeNode(-2);
root.right = new TreeNode(-3);
int pathSum = new SumOfRoad().pathSum(root, -1);
System.out.println(pathSum);
}
public int pathSum(TreeNode root, int targetSum) {
// 使用 HashMap 记录路径上的前缀和及其出现次数
Map<Long, Integer> prefixSumCount = new HashMap<>();
// 初始化空路径的前缀和为 0,出现 1 次
prefixSumCount.put(0L, 1);
// 调用递归函数,初始前缀和为 0
return dfs(root, 0, targetSum, prefixSumCount);
}
// 递归函数,计算以当前节点为终点的满足条件的路径数量
// currSum: 从根到当前节点的前缀和
// targetSum: 目标和
// prefixSumCount: 存储前缀和及其出现次数的哈希表
private int dfs(TreeNode node, long currSum, int targetSum, Map<Long, Integer> prefixSumCount) {
// 如果节点为空,直接返回 0
if (node == null) {
return 0;
}
// 更新当前路径的前缀和
currSum += node.val;
// 计算以当前节点为终点的满足条件的路径数量
// 查找是否存在前缀和 prevSum,使得 currSum - prevSum = targetSum
int pathCount = prefixSumCount.getOrDefault(currSum - targetSum, 0);
// 将当前前缀和加入哈希表,更新出现次数
prefixSumCount.put(currSum, prefixSumCount.getOrDefault(currSum, 0) + 1);
// 递归处理左子树和右子树,累加路径数量
pathCount += dfs(node.left, currSum, targetSum, prefixSumCount);
pathCount += dfs(node.right, currSum, targetSum, prefixSumCount);
// 回溯:移除当前前缀和,恢复哈希表状态
prefixSumCount.put(currSum, prefixSumCount.get(currSum) - 1);
return pathCount;
}
}title49 - 二叉树的最近公共祖先
TheLeatestCommonAncestor.java
java
package leecode100.title49;
import hot100.DataStruct.TreeNode;
import java.util.Stack;
/**
* 最近公共祖先
* 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
* 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
*/
public class TheLeatestCommonAncestor {
/**
* 思路:利用深度优先搜索递归,利用栈保存遍历到目标节点的路径。
* 最后通过出栈对比两个栈,找到最近公共祖先
*/
public static void main(String[] args) {
TreeNode root = new TreeNode(3);
root.left = new TreeNode(5);
root.right = new TreeNode(1);
root.left.left = new TreeNode(6);
root.left.right = new TreeNode(2);
root.left.right.left = new TreeNode(7);
root.left.right.right = new TreeNode(4);
root.right = new TreeNode(1);
root.right.left = new TreeNode(0);
root.right.right = new TreeNode(8);
TreeNode treeNode = new TheLeatestCommonAncestor().lowestCommonAncestor(root, root.left.left, root.left.right.right);
System.out.println(treeNode.val);
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
Stack<TreeNode> currentpathp = new Stack<>();
Stack<TreeNode> currentpathq = new Stack<>();
Stack<TreeNode> pathp = new Stack<>();
Stack<TreeNode> pathq = new Stack<>();
dfs(pathp, currentpathp, root, p);
dfs(pathq, currentpathq, root, q);
while (!pathp.isEmpty() && !pathq.isEmpty()) {
TreeNode nodep = pathp.peek();
TreeNode nodeq = pathq.peek();
if (nodep == nodeq) {
return nodep;
}
if (pathp.size() > pathq.size()) {
pathp.pop();
} else if (pathp.size() < pathq.size()) {
pathq.pop();
} else {
pathp.pop();
pathq.pop();
}
}
return root;
}
/**
* 通过dfs找到目标节点的路径
*
* @param pathp
* @param root
* @param p
*/
private void dfs(Stack<TreeNode> pathp, Stack<TreeNode> currentpathp, TreeNode root, TreeNode p) {
if (root == null) {
return;
}
if (root == p) {
currentpathp.push(root);
//结束加入路径的方式是交给pathp栈
pathp.addAll(currentpathp);
return;
}
currentpathp.push(root);
dfs(pathp, currentpathp, root.left, p);
dfs(pathp, currentpathp, root.right, p);
currentpathp.pop(); //回溯
}
}title50 - 二叉树中的最大路径和
TheLargestSumofRoad.java
java
package leecode100.title50;
import hot100.DataStruct.TreeNode;
/**
* 题目:二叉树最大路径和
* 二叉树中的路径被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中至多出现一次 。该路径至少包含一个节点,且不一定经过根节点。
* 路径和是路径中各节点值的总和。
* 给你一个二叉树的根节点 root ,返回其最大路径和。
* 输入:root = [1,2,3]
* 输出:6
* 解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
*/
public class TheLargestSumofRoad {
/**
* 思路:后序遍历,先求左右子树,再求根节点。
* 计算左子树最大单边路径和,再求右子树最大单边路径和,最后基于当前的节点,以及左右子树的单边路径和,计算当前节点的最大路径和,并且更新全局的路径。
* 对于每个节点:
* 递归计算左子树和右子树的最大单边路径和(如果子树为空,返回0)。
* 单边路径和只考虑正贡献(如果子树路径和为负,则忽略,视作0)。
* 当前节点的最大单边路径和 = 当前节点值 + max(左子树单边路径和, 右子树单边路径和, 0)。
* 当前节点的最大路径和 = 当前节点值 + 左子树单边路径和 + 右子树单边路径和。
* 更新全局最大路径和,比较当前节点的最大路径和与全局记录。
* 递归返回单边路径和,供上层节点使用。
*/
public static void main(String[] args) {
}
public static int maxPath = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
maxPath = Integer.MIN_VALUE;
findMaxPathSumHelper(root);
return maxPath;
}
private int findMaxPathSumHelper(TreeNode root) {
if (root == null) {
return 0;
}
//保存左右子树的最大单边路径和和
int leftPathSum = Math.max(findMaxPathSumHelper(root.left), 0);
int rightPathSum = Math.max(findMaxPathSumHelper(root.right), 0);
//计算当前节点的最大路径和
int currentSum = root.val + leftPathSum + rightPathSum;
//更新全局变量
maxPath = Math.max(maxPath, currentSum);
//返回当前节点的最大单边路径 供上层节点使用。
return root.val + Math.max(leftPathSum, rightPathSum);
}
}
```[1_50.md](1_50.md)